
- What Is an AI Chatbot Conversations Archive?
- Why Businesses Are Prioritizing AI Conversation Archives in 2026
- Explosion of Conversational AI
- Rising Customer Expectations
- AI Governance and Compliance Pressure
- Need for Better AI Training Data
- Shift Toward Conversational Search
- Key Benefits of AI Chatbot Conversation Archives
- Improve AI Accuracy
- Better Customer Support
- Identify Customer Pain Points
- Smarter Business Decisions
- Faster Agent Training
- Knowledge Retention
- Quality Assurance
- Personalization Opportunities
- Better SEO and Content Strategy
- Real-World Use Cases of AI Chatbot Conversation Archives
- Ecommerce Support Automation
- SaaS Customer Success
- Healthcare Assistance Logs
- Banking and Financial Compliance
- Internal Enterprise AI Assistants
- Education and Learning Bots
- AI Sales Assistants
- How Archived Conversations Improve AI Training
- Identifying Failed Responses
- Improving Intent Detection
- Building Better Prompt Flows
- Fine-Tuning AI Models
- Reducing Hallucinations
- Improving Retrieval-Augmented Generation
- Security, Privacy and Compliance Considerations
- Data Encryption
- Access Controls
- User Consent
- Data Retention Policies
- GDPR and Regulatory Considerations
- Sensitive Information Risks
- Legal Discovery Risks
- AI Governance Best Practices
- Common Challenges in Managing AI Chatbot Archives
- Massive Data Volumes
- Storage Costs
- Context Drift
- Data Cleanup Issues
- Search and Retrieval Complexity
- Maintaining Privacy Standards
- Best Practices for Managing AI Chatbot Conversation Archives
- Future Trends in AI Conversation Archiving
- AI Memory Systems
- Personalized AI Experiences
- Semantic Search for Chat Archives
- Voice and Multimodal Archives
- AI Compliance Automation
- Enterprise AI Governance Platforms
- How to Choose the Right AI Chat Archive Solution
- Scalability
- Security Features
- Search Capabilities
- Compliance Support
- Integration with Existing Systems
- Analytics and Reporting
- Final Thoughts
- Build a Conversation Archive That Delivers Real Value
- Frequently Asked Questions
- What is an AI chatbot conversations archive?
- Why should businesses archive chatbot conversations?
- Are AI chatbot archives secure?
- How long should chatbot conversations be stored?
- Can archived chatbot conversations improve AI models?
- What are the compliance risks of storing chatbot conversations?
- How do businesses analyze chatbot conversation data?
- What is the difference between chatbot logs and conversation archives?
- Can chatbot archives improve customer experience?
- What tools are used to manage AI conversation archives?
Every business running a chatbot today is sitting on a goldmine and doesn’t realize it. The conversations that flow through your support widget, WhatsApp assistant, or AI agent aren’t just transactional exchanges. They’re behavioral data, training material, audit evidence, and competitive intelligence rolled into one stream.
Most companies treat these chats like email — read once, archived somewhere, forgotten. That’s a costly mistake. Salesforce’s 2025 State of Service report showed organizations that systematically analyze chatbot conversation data improve first-contact resolution by 41 percent on average. The ones that don’t are leaving insight on the table.
An AI chatbot conversations archive is more than storage. Done right, it becomes the intelligence layer behind scalable AI & Chatbot Development,making your AI smarter, your support sharper, your compliance audits painless, and every customer interaction more personalized.
This guide walks through what an AI chatbot conversations archive actually is, why it matters now more than ever, how to build one responsibly, and where the regulatory landmines hide. No fluff. Just what we’ve learned helping US and global businesses operationalize conversational AI properly.
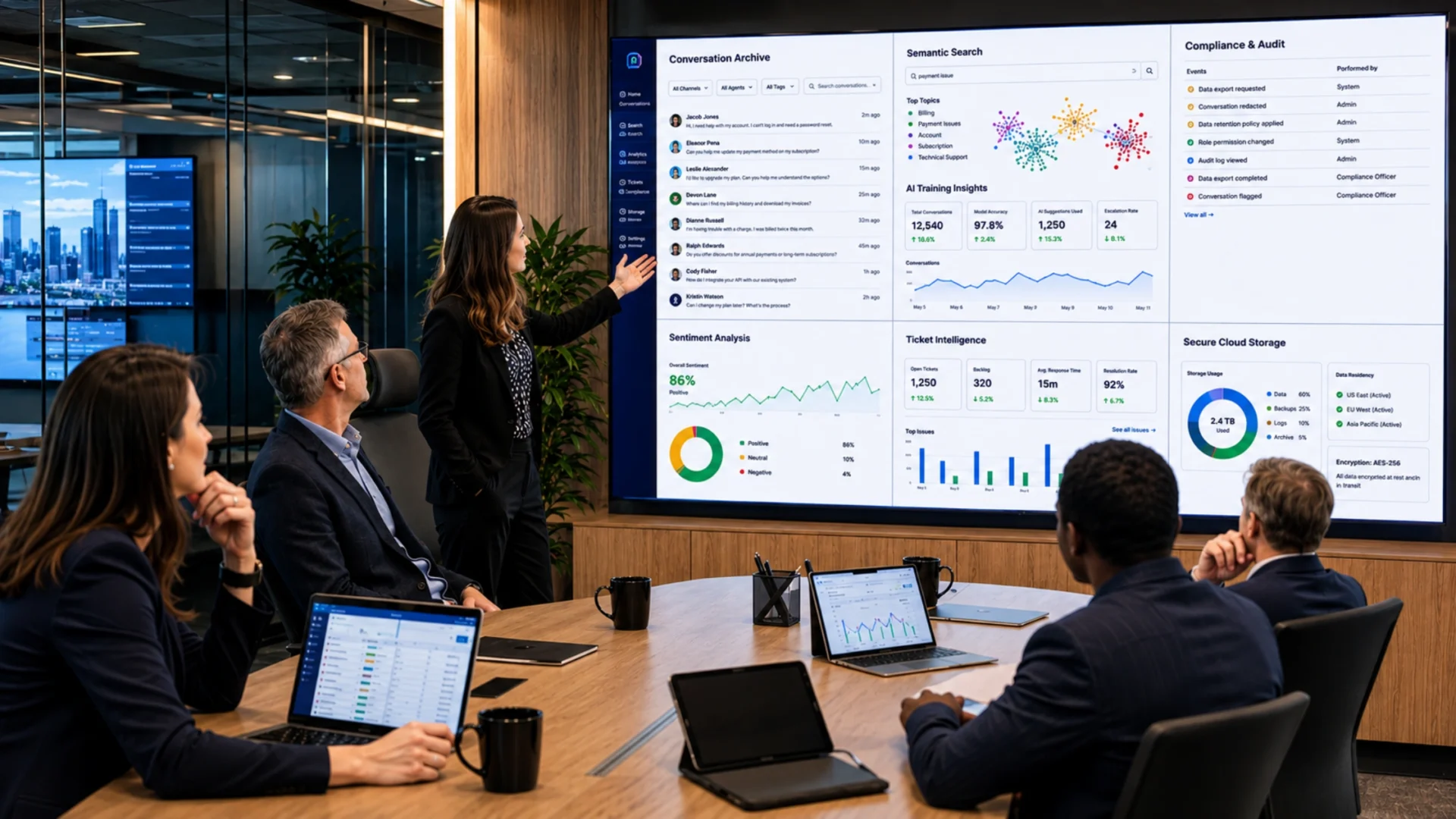
What Is an AI Chatbot Conversations Archive?
An AI chatbot conversations archive is a structured, searchable, governed repository of every chat exchange between users and your AI systems. It captures prompts, responses, timestamps, session IDs, intent classifications, sentiment scores, resolution flags, and the metadata that turns raw chat logs into business intelligence.
There’s a meaningful difference between a basic chat log and a proper conversation archive. Logs are dumps. Archives are organized, annotated, and built to be queried.
Think about it this way. A log tells you a conversation happened. An archive tells you what was said, why it mattered, how it resolved, and what your AI model can learn from it.
Quick clarification: If your chatbot platform shows “transcripts” but you can’t run queries across them, filter by sentiment, or feed them back into training pipelines, you don’t have an archive. You have storage.
A modern conversation archive typically captures the following data points:
- User prompts and AI responses in their original form
- Session and user identifiers linked to your CRM or customer data platform
- Timestamps for every turn, not just session start
- Intent classifications assigned by the bot’s NLU layer
- Sentiment markers and confidence scores
- Resolution outcomes — solved, escalated, abandoned
- Channel metadata (web widget, WhatsApp, in-app, voice)
Why Businesses Are Prioritizing AI Conversation Archives in 2026
Something shifted in the last 18 months. Conversation archives went from optional analytics tool to operational necessity. A few forces converged.
Explosion of Conversational AI
Gartner estimates conversational AI deployments grew 64 percent year-over-year through 2025. Brands that ran one chatbot now run five — web support, WhatsApp commerce, internal HR assistants, sales qualification bots, and product discovery agents. Without a central archive, each one becomes its own data silo.
Rising Customer Expectations
Customers expect the AI to remember them. Honestly, they’re often surprised when it doesn’t. If a buyer messaged your bot last month about an order issue, they shouldn’t have to re-explain on the next visit. Conversation memory is now a competitive expectation, not a luxury feature.
AI Governance and Compliance Pressure
The EU AI Act, US state privacy laws like CCPA/CPRA, and sector-specific rules in healthcare and finance all require demonstrable audit trails of AI-customer interactions. Without an archive, you can’t prove what the AI said or what data it accessed. That’s a real legal exposure now.
Need for Better AI Training Data
Generic LLMs hallucinate on domain-specific questions. The fix isn’t bigger models. It’s better domain data. Your archived conversations are the highest-value training material you have for fine-tuning, retrieval-augmented generation, and intent model improvement.
Shift Toward Conversational Search
Search itself is becoming conversational. ChatGPT, Perplexity, Gemini, and Google AI Overviews now answer questions instead of returning links. Companies that understand how customers actually phrase questions — captured through their chat archives — produce content and product experiences that align with conversational discovery patterns.
Key Benefits of AI Chatbot Conversation Archives
The returns aren’t theoretical. Here’s where archives create measurable value.
Improve AI Accuracy
Failed responses are the most valuable data points in your archive. Every time the bot answered “I don’t understand” or escalated unnecessarily, that’s a training signal. Teams that systematically review and re-label these cases typically lift intent recognition accuracy by 15 to 25 percent in six months.
Better Customer Support
Archives let support agents see the full history before they engage. No more asking the customer to repeat themselves. That alone reduces handle time by 20 to 30 percent on most help desks we’ve audited.
Identify Customer Pain Points
Cluster analysis on archived conversations reveals what customers actually struggle with. Not what your team thinks they struggle with. Different thing entirely.
Smarter Business Decisions
Product teams use archive insights to prioritize roadmap items. If 12 percent of chats mention a missing feature, that’s a clear signal. Marketing teams use archives to refine messaging based on the language customers actually use.
Faster Agent Training
New support agents learn faster when they can review real resolved conversations. It’s the difference between abstract training and pattern recognition.
Knowledge Retention
When experienced agents leave, their expertise often walks out the door. Archives preserve institutional knowledge in a way that’s searchable and reusable.
Quality Assurance
Sampling and reviewing archived conversations is how you catch tone problems, factual errors, or off-brand AI responses before they become PR incidents.
Personalization Opportunities
Behavioral patterns from past chats power smarter product recommendations, targeted promotions, and tailored onboarding flows. Done with consent, this builds loyalty. Done without it, you’ve got a privacy problem.
Better SEO and Content Strategy
Conversation archives are an underrated content goldmine. The exact questions customers ask your bot are the same questions they’re typing into Google. Mining your archive for high-frequency questions feeds your answer engine optimization efforts directly.
Real-World Use Cases of AI Chatbot Conversation Archives
Different industries pull different value from the same underlying data. A few patterns worth understanding.
Ecommerce Support Automation
Online retailers use archives to identify return reasons, sizing issues, and shipping confusion. One Shopify Plus client we worked with reduced return rates by 14 percent after analyzing two quarters of chat data and adjusting product descriptions accordingly.
SaaS Customer Success
SaaS teams flag at-risk accounts by tracking conversation sentiment over time. A customer who messaged support five times last month with frustrated tone is a churn risk worth a proactive call.
Healthcare Assistance Logs
HIPAA-compliant archives are mandatory for any healthcare AI assistant. Beyond compliance, they help clinicians spot symptom patterns and refine triage protocols.
Banking and Financial Compliance
Financial services are required to maintain detailed records of customer communications. Archives serve as the audit trail regulators expect, and they’re invaluable when investigating disputes or fraud claims.
Internal Enterprise AI Assistants
Employee-facing AI assistants generate archives that show what knowledge gaps exist inside the organization. HR, IT, and Operations teams use these to update internal documentation and reduce repetitive ticket volume.
Education and Learning Bots
EdTech platforms track learner questions to identify where curriculum confusion concentrates. That’s how you build adaptive learning paths instead of one-size-fits-all courses.
AI Sales Assistants
Sales bots qualify leads, answer pre-purchase questions, and route hot prospects. Archived conversations feed CRM data and reveal objection patterns the sales team can prepare for.
How Archived Conversations Improve AI Training
This is where most teams underinvest. Your archive isn’t just a record. It’s the training corpus for the next version of your AI.
Identifying Failed Responses
Sort archived conversations by escalation rate and you’ll find the queries your bot can’t handle. These are your highest-priority training examples. Fix them and accuracy improves measurably.
Improving Intent Detection
Real customers don’t phrase questions the way your NLU training data assumes. Archived conversations show the messy, slangy, typo-ridden reality. Adding these examples to your training set narrows the gap between lab accuracy and production accuracy.
Building Better Prompt Flows
For generative AI bots, the system prompts and conversation flows that work best in production aren’t always the ones engineers designed. Archives reveal which prompt patterns lead to resolution and which lead to user frustration.
Fine-Tuning AI Models
When you fine-tune a model on your domain data, the quality of that data determines the quality of the result. Clean, labeled, anonymized conversation archives are ideal source material. Garbage in, garbage out — but quality archives produce noticeably better domain-specific responses.
Reducing Hallucinations
Hallucinations happen when the model fills in gaps with plausible-sounding fiction. Grounding responses in retrieved archive content (your actual customer conversations and resolutions) cuts hallucination rates significantly.
Improving Retrieval-Augmented Generation
RAG systems retrieve relevant context before generating responses. Conversation archives, properly vectorized and indexed, become a retrieval layer that grounds the model in your business reality. Our team often pairs this approach with AI agent development work to build context-aware assistants that perform better than generic alternatives.
Security, Privacy and Compliance Considerations
Here’s where most teams underestimate the work. Archives contain sensitive data. Treating them casually is how breach headlines happen.
Data Encryption
Encrypt at rest. Encrypt in transit. Use AES-256 for storage and TLS 1.3 for transmission. This is the baseline. Anything less is negligence in 2026.
Access Controls
Not every team member needs full archive access. Role-based access controls, audit logging on queries, and just-in-time access provisioning prevent the casual data spelunking that leads to insider incidents.
User Consent
Tell users their conversations are being stored. Tell them why. Give them a way to opt out or request deletion. CCPA, CPRA, GDPR, and most state privacy laws now require this. Hidden archiving is a compliance violation waiting to surface.
Data Retention Policies
Define how long different conversation types are stored. Sales leads might warrant 24 months. Healthcare queries might require longer retention by law. Marketing chatbot interactions probably don’t need to live forever.
Worth noting: A 2025 Guardian report highlighted that AI chatbot conversations are increasingly subject to legal discovery in litigation. What your customers tell your bot can be subpoenaed. Build retention policies with that reality in mind.
GDPR and Regulatory Considerations
GDPR’s right to erasure applies to chatbot archives. If a user requests deletion, you need infrastructure to find and remove their conversations across the system. That’s harder than it sounds when data flows into vector databases and fine-tuning datasets.
Sensitive Information Risks
Customers volunteer surprising things in chat. Credit card numbers, social security numbers, medical conditions, passwords. Automated redaction at the point of capture is essential. Don’t archive PII you don’t need.
Legal Discovery Risks
Litigation hold procedures need to extend to chatbot archives. If you’re not preserving conversations relevant to active or anticipated legal matters, you’re exposing the company to spoliation sanctions.
AI Governance Best Practices
Treat your archive as a governed AI asset. Document what’s stored, who can access it, how it’s used in training, and what controls exist. Companies that take this seriously can answer regulator questions in hours, not weeks. Our AI strategy consulting team helps organizations build these governance frameworks from the ground up.
Common Challenges in Managing AI Chatbot Archives
Setting up an archive is the easy part. Running one at scale exposes friction points that catch most teams off guard.
Massive Data Volumes
A mid-sized ecommerce brand running a single chatbot can generate 5 to 20 million messages a year. Multiply that across channels and you’re managing terabytes. Storage strategy matters.
Storage Costs
Hot storage for recent conversations. Warm storage for the last quarter. Cold archival for older data that’s required by retention policy but rarely accessed. Mixing tiers properly can cut storage costs by 60 to 80 percent without sacrificing accessibility.
Context Drift
Conversations from two years ago reference products that don’t exist anymore, policies that changed, and team members who left. If you feed all of it indiscriminately into model training, you’ll teach the AI outdated information.
Data Cleanup Issues
Real conversations contain typos, slang, foreign language switches, and noise. Cleaning this without losing the natural language patterns that make the data valuable requires careful pipeline design.
Search and Retrieval Complexity
Keyword search across millions of conversations is slow and shallow. Semantic search with vector embeddings is more useful but requires infrastructure most teams don’t have in-house. This is often where data engineering and MLOps support becomes necessary.
Maintaining Privacy Standards
Privacy controls degrade over time without active maintenance. PII redaction rules need updates. Access permissions drift. Retention policies get forgotten. Treat archive governance as ongoing operational work, not a one-time setup.
Best Practices for Managing AI Chatbot Conversation Archives
What separates archives that deliver value from those that collect dust? A handful of operational habits.
|
1
|
Define Retention Policies Up FrontDecide what gets kept, for how long, and why. Document the reasoning. Review annually. |
|
2
|
Organize Conversations by IntentTag every conversation with intent classification. That structure is what makes the archive queryable later. |
|
3
|
Remove Sensitive Data AutomaticallyBuild PII detection and redaction at ingestion. Don’t store data you’ll regret keeping. |
|
4
|
Use AI-Powered SearchVector embeddings and semantic search make archives genuinely useful. Without them, you’re storing data you can’t find. |
|
5
|
Regularly Review Conversation QualitySample conversations weekly. Spot tone issues, factual errors, and emerging customer themes early. |
|
6
|
Build Human Review ProcessesAutomated quality checks miss nuance. Pair them with human reviewers who flag edge cases. |
|
7
|
Maintain Transparent AI PoliciesPublish your AI archiving and usage policies publicly. Customers trust brands that explain what’s happening with their data. |
Future Trends in AI Conversation Archiving
The field is moving fast. A few directions worth watching.
AI Memory Systems
Anthropic, OpenAI, and others are building persistent memory into their assistants. Enterprise teams will need archive infrastructure that supports long-term, cross-session memory while still respecting deletion requests. That balance isn’t trivial.
Personalized AI Experiences
The next wave of customer experiences will draw on archived history to anticipate needs. Done with consent, this feels helpful. Done poorly, it feels invasive. The brands that nail this distinction will win loyalty.
Semantic Search for Chat Archives
Vector databases like Pinecone, Weaviate, and Qdrant are becoming standard infrastructure for chat archive retrieval. Expect search experiences across archives to feel more like asking a knowledgeable colleague and less like grep.
Voice and Multimodal Archives
Voice AI, video assistants, and image-based interactions are growing. Archives will need to handle transcripts, audio waveforms, screenshots, and structured metadata across modalities.
AI Compliance Automation
Tools that automatically tag conversations for regulatory categories, flag sensitive content, and generate compliance reports from archives are emerging. Expect this category to consolidate around a few enterprise platforms over the next two years.
Enterprise AI Governance Platforms
Standalone AI governance products are giving way to integrated platforms that combine archive management, model monitoring, bias detection, and regulatory reporting. Worth evaluating early if your AI footprint is growing.
How to Choose the Right AI Chat Archive Solution
The market has expanded fast. Picking the right solution depends on your scale, regulatory requirements, and integration needs.
Scalability
If you’re processing 10,000 conversations a month today and planning to hit 500,000, choose infrastructure that scales without rebuilding. Cloud-native solutions on AWS, GCP, or Azure typically scale better than on-premise alternatives.
Security Features
Look for SOC 2 Type II certification, ISO 27001 compliance, and HIPAA support if you’re in healthcare. Encryption at rest and in transit should be table stakes, not selling points.
Search Capabilities
Test the search before you buy. Run real queries. If you can’t find conversations by intent, sentiment, or semantic meaning, the platform isn’t ready for serious use.
Compliance Support
Built-in tools for retention policy enforcement, user data deletion, and audit reporting save enormous amounts of operational work. Check these capabilities carefully.
Integration with Existing Systems
Your archive needs to connect to your CRM, customer data platform, BI tools, and model training pipelines. Check API quality, webhook reliability, and supported connectors.
Analytics and Reporting
Out-of-the-box dashboards for conversation volume, sentiment trends, intent distribution, and resolution rates accelerate value. Some platforms still require custom BI work for basic insights. Avoid those if you can.
Final Thoughts
Conversations are business intelligence. Every message that flows through your chatbot carries signal about what customers want, what they struggle with, what they’re worth, and how your AI is performing.
Companies that treat chatbot conversations as exhaust are leaving compounding value on the table. Companies that build proper archives — with governance, security, searchability, and reuse in mind — turn that exhaust into fuel for smarter AI, better support, sharper marketing, and faster product decisions.
The shift toward AI-first customer experience is permanent. Persistent conversational memory is becoming the new baseline expectation. Brands without a structured approach to archiving will fall behind brands that built this capability deliberately.
Start with a clear archive policy. Pick infrastructure that fits your scale. Build governance into the foundation, not as an afterthought. And treat your archive as the strategic asset it actually is.
Build a Conversation Archive That Delivers Real Value
Whether you’re starting fresh or fixing what’s already in place, our team can help. We design, build, and govern AI conversation archives that hold up under regulatory scrutiny and feed measurable business growth.
Frequently Asked Questions
What is an AI chatbot conversations archive?
An AI chatbot conversations archive is a structured, searchable repository that stores every interaction between users and AI chatbots. It captures prompts, responses, timestamps, intent classifications, sentiment markers, and metadata so businesses can analyze conversations, train AI models, support compliance audits, and improve customer experience.
Why should businesses archive chatbot conversations?
Businesses archive chatbot conversations to improve AI accuracy, identify customer pain points, support compliance audits, enable personalized experiences, and feed training data back into AI models. Properly archived conversations also serve as legal records, sales intelligence, and a knowledge base for support teams.
Are AI chatbot archives secure?
AI chatbot archives can be highly secure when built with encryption at rest and in transit, role-based access controls, PII redaction at ingestion, and audit logging. Security depends entirely on implementation. Poorly configured archives are a major breach risk, while properly governed archives meet enterprise security standards including SOC 2, HIPAA, and GDPR.
How long should chatbot conversations be stored?
Storage duration depends on industry, jurisdiction, and conversation type. Healthcare and financial services often require multi-year retention by law. Ecommerce support chats typically stay useful for 12 to 24 months. Marketing chatbot interactions may need shorter retention. Document a clear retention policy for each conversation category and review it annually.
Can archived chatbot conversations improve AI models?
Yes. Archived conversations are among the highest-value training data available for fine-tuning AI models on your domain. They contain real customer language, edge cases, failed responses, and resolution patterns that improve intent recognition, reduce hallucinations, and ground generative AI in your actual business context.
What are the compliance risks of storing chatbot conversations?
Compliance risks include GDPR violations from missing deletion workflows, CCPA penalties for failing to honor opt-out requests, HIPAA breaches if healthcare data isn’t properly secured, and legal exposure if archives aren’t preserved for active litigation. A clear retention and deletion policy paired with strong access controls mitigates most of these risks.
How do businesses analyze chatbot conversation data?
Businesses analyze chatbot conversation data through semantic search, intent clustering, sentiment analysis, escalation pattern review, and trend dashboards. Modern platforms use vector embeddings to find similar conversations across millions of records and surface insights that keyword search would miss entirely.
What is the difference between chatbot logs and conversation archives?
Chatbot logs are temporary records of conversations with limited searchability and basic metadata. Conversation archives are structured, governed repositories built for analytics, AI training, compliance audits, and long-term retention. Logs tell you a conversation happened. Archives tell you what was said, why it mattered, and what your business can learn from it.
Can chatbot archives improve customer experience?
Absolutely. Archives enable support agents to see full conversation history before engaging, power personalized recommendations based on past behavior, identify recurring pain points that need fixing, and feed AI systems that anticipate customer needs. Brands using archives well typically see measurable lifts in CSAT, retention, and first-contact resolution.
What tools are used to manage AI conversation archives?
Common tools include vector databases like Pinecone, Weaviate, and Qdrant for semantic search, cloud storage solutions on AWS S3 or Google Cloud Storage for raw archives, conversational analytics platforms like Cresta and Observe.AI, and custom MLOps pipelines for AI training data preparation. Many enterprise teams combine these into governed archive platforms tailored to their specific compliance and scale needs.



